
1 简介
众所周知(你不知也当你知),MongoDB是以文档(Document)组织数据的。除了常用于存储Json数据,它也是可以存储普通文件的。我们可以把一些文件以BSOON的格式存入MongoDB,十分方便,比较说图片、文本文件等。但MongoDB的BSON Document有大小限制,最大不能超过16MB。这对我们存储大文件是不方便的。还好,MongoDB为我们提供了GridFS文件存储组件,让我们可以存储超过16MB的文件,小文件当然也可以了。接下来让我们一起学习一下这个GridFS存储。
2 基本原理与概念
GridFS原理比较简单,就是把大文件拆成小文件来存储而已。当我们存入一个文件时,默认使用集合fs.files和fs.chunks来存储文件。其中fs.files存储的是文件的信息,fs.chunks用来存放文件内容,以BSON格式存放。
fs.files的一条记录如下:
{
"_id" : ObjectId("5ec6b44af3760d5999bd1c91"),
"length" : NumberLong(1048576),
"chunkSize" : 261120,
"uploadDate" : ISODate("2020-05-21T17:03:06.217Z"),
"filename" : "pkslow.txt",
"metadata" : {}
}
字段解释:
_id:主键ID;
length:文件大小;
chunkSize:chunk的大小,决定要分几个chunk来存放文件;
uploadDate:文件上传时间;
filename:文件名;
metadata:文件其它信息,可以自定义加上,这样有利于后续的检索和使用等。
fs.chunks的一条记录如下:
{
"_id" : ObjectId("5ec6b44af3760d5999bd1c94"),
"files_id" : ObjectId("5ec6b44af3760d5999bd1c91"),
"n" : 2,
"data" : { "$binary" : "xxxxxxxxx", "$type" : "00" }
}
字段解释:
_id:主键ID;
files_id:所存内容对应的文件ID,可以看到与fs._id的值是一样的;
n:第几个chunk的索引,从0开始;
data:文件内容;
从感观上看了两个集合的字段,相信大家基本知道GridFS是怎么组织数据的了。当我们存入一个文件时,如果文件较小,小于chunkSize,则会把文件信息存入fs.files,只有一条记录;文件内容会存入fs.chunks,也只有一条记录。如果存的文件大于chunkSize,也会在fs.files生成一条记录,但在fs.chunks中会生成多条记录来存放文件内容。如下图所示:
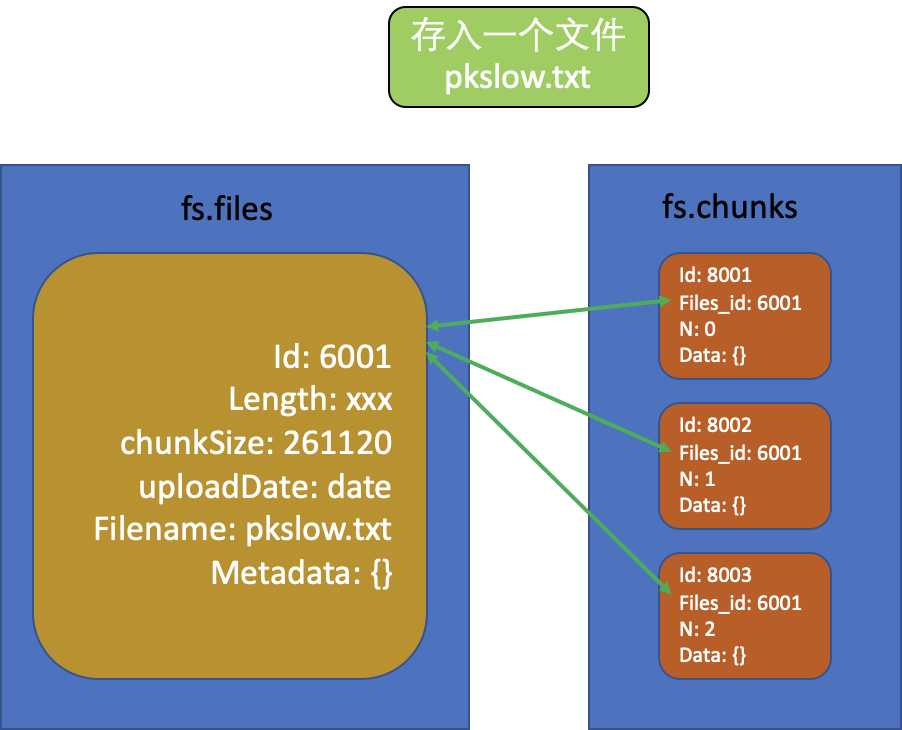
MongoDB为我们建立了相关索引,可以加速查询,如fs.files的文件名和上传时间;fs.chunks的文件ID和n。
3 常用mongofiles命令
讲了基本原理,我们来实际操作一下,使用MongoDB给我们准备好的命令来做一些操作。当然,首先要有一个安装好的数据库,可以参考《用Docker安装一个MongoDB最新版玩玩》。
我们都是使用mongofiles命令进行操作的,需要指定比较多的参考,例如下面的命令用于列出所有文件:
mongofiles --username user --password 123456 --host 127.0.0.1 --port 27017 --authenticationDatabase admin --db testdb list
为了不要每次都输入这么长的命令,我们加个别名:
alias mf='mongofiles --username user --password 123456 --host 127.0.0.1 --port 27017 --authenticationDatabase admin --db testdb'
列出文件:
mf list
存入文件:存入的文件名与本地文件名一样。
mf put pksow.txt
读取文件:
mf get pkslow.txt
查找文件:
mf search pkslow
删除文件:
mf delete pkslow.txt
指定自定义文件名:
mf --local pkslow.txt put /com/pkslow.txt
4 总结
发挥你的想象力,GridFS能做的事很多,存图片、音频、视频等,有时我们只想查看大文件的部分内容,也能方便实现。
注:本文使用的MongoDB版本为4.2.1。