
Java JVM 核心知识点
JVM内存
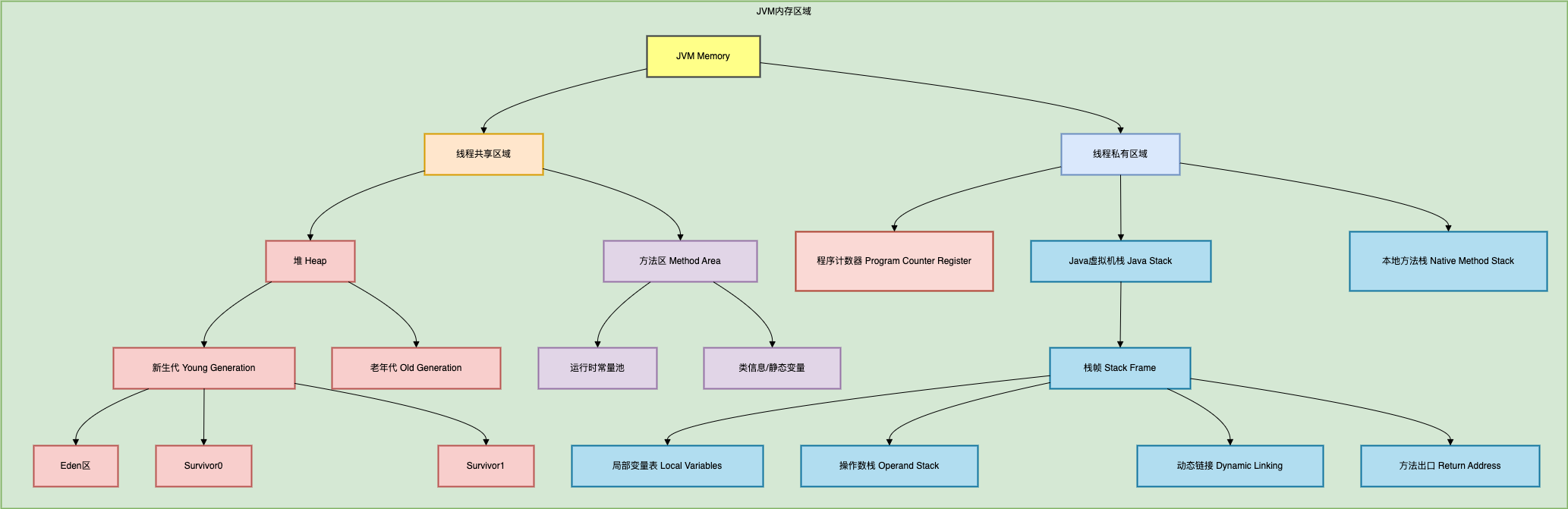
一、JVM 内存区域与作用
线程共享区域
- 堆 (Heap)
- 存储对象实例和数组
- 分代结构:
- 新生代 (Young Generation)
- Eden区:新对象分配区
- Survivor区 (S0/S1):存活对象过渡区
- 老年代 (Old Generation):长期存活对象
- 新生代 (Young Generation)
- 方法区 (Method Area)
- JDK8前:永久代 (PermGen)
- JDK8+:元空间 (Metaspace,使用本地内存)
- 存储:类信息、运行时常量池、静态变量
线程私有区域
- 程序计数器 (PC Register)
- 记录当前线程执行的字节码行号
- Java 虚拟机栈 (Java Stack)
- 栈帧组成:
- 局部变量表
- 操作数栈
- 动态链接
- 方法返回地址
- 栈帧组成:
- 本地方法栈 (Native Method Stack)
- 为 Native 方法(如C/C++代码)服务
二、垃圾回收算法
| 算法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 标记-清除 | 标记可达对象,清除未标记对象 | 简单 | 内存碎片化 |
| 复制算法 | 将存活对象复制到另一块内存区域 | 无碎片,高效 | 内存利用率50% |
| 标记-整理 | 标记后移动存活对象到内存一端 | 无碎片,适合老年代 | 移动对象成本高 |
| 分代收集 | 新生代用复制算法,老年代用标记-清除/整理 | 综合效率高 | 需配合其他算法 |
| 三色标记法 | 黑白灰三色标记对象状态(G1/ZGC使用) | 并发标记,STW时间短 | 实现复杂 |
三、JDK 版本选择建议
| JDK版本 | GC 特性 | 适用场景 |
|---|---|---|
| JDK8 | 默认 Parallel GC,可选 CMS/G1 | 传统应用,兼容性要求高 |
| JDK11 | 默认 G1 GC,引入 ZGC(实验性) | 中等延迟敏感型应用 |
| JDK17 | ZGC/Shenandoah 成为正式特性,G1 持续优化 | 低延迟、大堆内存应用 |
| JDK21 | ZGC 支持分代回收,G1 改进暂停预测 | 超低延迟(<1ms)应用 |
四、GC 回收器对比
| 回收器 | 算法 | 适用区域 | 特点 | 适用场景 | 支持JDK |
|---|---|---|---|---|---|
| Serial | 复制+标记-整理 | 新生代/老年代 | 单线程,STW时间长 | 客户端小程序 | 全版本 |
| Parallel | 复制+标记-整理 | 新生代/老年代 | 多线程,吞吐量优先 | 后台计算型应用 | 全版本 |
| CMS | 标记-清除 | 老年代 | 并发收集,低延迟 | 响应时间敏感型应用 | JDK5~JDK14 |
| G1 | 分代+分区 | 全堆 | 可预测停顿时间,平衡型 | 大堆内存应用 | JDK7+ |
| ZGC | 着色指针+读屏障 | 全堆 | 并发标记整理,STW <1ms | 超大堆内存低延迟 | JDK11+ |
| Shenandoah | 转发指针+读屏障 | 全堆 | 与 ZGC 类似,社区驱动 | Red Hat 系环境 | JDK12+ |
五、关键选择原则
- 吞吐量优先:Parallel GC(JDK8)
- 低延迟要求:G1(JDK11+)或 ZGC(JDK17+)
- 超大堆内存:ZGC/Shenandoah(堆内存 >32GB)
- 兼容性优先:JDK8 或 JDK11 LTS 版本
TLAB介绍
以下是关于 TLAB(Thread-Local Allocation Buffer) 的详细介绍:
一、TLAB 的定义
TLAB(线程本地分配缓冲区) 是 JVM 堆内存中为每个线程单独分配的一块内存区域,位于 新生代的 Eden 区。每个线程在创建对象时,优先在自己的 TLAB 中分配内存,避免多线程竞争全局堆内存指针,从而提升对象分配效率。
二、TLAB 的作用
- 减少锁竞争
避免多个线程同时操作堆内存的分配指针,降低同步开销。 - 提升分配速度
线程在本地缓冲区分配内存无需加锁,分配操作更高效。 - 优化内存局部性
同一线程分配的对象集中在 TLAB 中,提高 CPU 缓存命中率。
三、工作原理
1. 分配流程
- 步骤 1:线程首次分配对象时,向 Eden 区申请一块 TLAB(默认大小由 JVM 动态计算)。
- 步骤 2:对象优先在 TLAB 内分配,仅需移动 TLAB 内部的指针(无锁操作)。
- 步骤 3:当 TLAB 剩余空间不足时:
- 若剩余空间小于 浪费阈值(默认 1%),直接废弃当前 TLAB。
- 否则,尝试在 Eden 区进行 慢路径分配(可能需要同步)。
- 步骤 4:废弃的 TLAB 空间会被其他线程复用或由 GC 回收。
2. 内存结构
Eden 区
├── Thread1 TLAB → [已分配对象 | 剩余空间]
├── Thread2 TLAB → [已分配对象 | 剩余空间]
└── 全局可分配空间(用于慢路径分配)
四、关键特性
1. 动态调整
- JVM 根据线程分配行为自动调整 TLAB 大小:
- 频繁分配大量对象的线程 → TLAB 增大。
- 分配较少的线程 → TLAB 缩小。
- 参数:
-XX:+ResizeTLAB(默认启用)。
2. 空间浪费控制
- 为避免 TLAB 剩余空间过多导致内存浪费,JVM 设定 最大浪费阈值。
- 参数:
-XX:TLABWasteTargetPercent(默认 1%)。
五、相关 JVM 参数
| 参数 | 作用 | 默认值 |
|---|---|---|
-XX:+UseTLAB |
启用 TLAB | JDK6+ 默认启用 |
-XX:TLABSize |
初始 TLAB 大小(字节) | 动态计算 |
-XX:-ResizeTLAB |
禁用 TLAB 动态调整 | 默认启用调整 |
-XX:TLABWasteIncrement |
每次分配失败时增加的浪费阈值 | 4(百分比单位) |
六、优缺点对比
| 优点 | 缺点 |
|---|---|
| 显著提升多线程分配性能 | 可能存在少量内存浪费 |
| 减少全局锁竞争 | 需结合 GC 策略优化 |
| 改善内存局部性 | 小对象分配优化更明显 |
七、适用场景
- 高并发应用
如 Web 服务器、实时数据处理系统,大量线程频繁创建对象。 - 短生命周期对象
临时对象在 TLAB 分配后,随 Minor GC 快速回收。 - 低延迟要求场景
通过减少锁竞争降低分配延迟。
八、监控与调优
1. 查看 TLAB 使用情况
jstat -gc <pid> # 关注 "TLAB" 相关指标
jcmd <pid> VM.tlab_info # 输出详细 TLAB 统计
2. 调优建议
- 增大 TLAB 初始大小
若应用频繁分配大对象:-XX:TLABSize=256k - 关闭动态调整
若分配模式稳定:-XX:-ResizeTLAB - 调整浪费阈值
减少空间浪费:-XX:TLABWasteTargetPercent=2
通过合理利用 TLAB,可以在多线程环境下显著提升对象分配效率,是高并发 Java 应用性能调优的重要环节。
对象的回收
在 Java 虚拟机(JVM)中,垃圾回收(GC)判断对象是否可以回收的核心逻辑是可达性分析(Reachability Analysis),而非简单的引用计数。以下是完整判断机制和流程:
一、可达性分析算法
JVM 通过 “GC Roots” 作为起点,遍历对象引用链。如果一个对象到 GC Roots 没有可达路径,则判定为可回收对象。
GC Roots 的类型:
- 栈帧中的局部变量
- 当前正在执行的方法的局部变量和参数(所有线程的虚拟机栈和本地方法栈)。
- 活跃线程对象
- 所有处于运行状态的线程对象(
Thread实例)。
- 所有处于运行状态的线程对象(
- 静态变量
- 类静态属性(
static修饰的字段)。
- 类静态属性(
- JNI 引用
- Native 方法中引用的 Java 对象(全局/局部 JNI 引用)。
- 系统类加载器
- Bootstrap 类加载器加载的类(如
java.lang.String)。
- Bootstrap 类加载器加载的类(如
- 同步锁对象
- 被
synchronized持有的对象(Monitor 对象)。
- 被
二、对象回收判定流程
graph TD
A[GC Roots] --> B[遍历引用链]
B --> C{对象是否可达?}
C -->|不可达| D[标记为可回收对象]
C -->|可达| E[保留对象]
D --> F[进入回收队列]
具体步骤:
- 标记阶段(Marking)
- 从所有 GC Roots 出发,递归遍历对象图,标记所有可达对象为存活状态。
- 筛选阶段(Sweeping/Compacting)
- 未被标记的对象会被判定为垃圾,根据 GC 算法进行回收(标记-清除/复制/标记-整理等)。
三、对象复活机制(finalize())
即使对象被标记为不可达,仍有一次复活机会:
public class Zombie {
static Zombie hook;
@Override
protected void finalize() throws Throwable {
hook = this; // 对象复活
}
}
复活规则:
- 对象首次被标记为不可达时,若重写了
finalize()方法且未被 JVM 调用过,会加入 Finalizer 队列。 - Finalizer 线程异步执行
finalize()方法,若对象在此方法中重新被引用,则复活。 - 复活仅生效一次,第二次 GC 时即使实现
finalize()也会被回收。
四、引用类型与回收强度
| 引用类型 | 特点 | 回收条件 |
|---|---|---|
| 强引用 | Object obj = new Object() |
对象不可达时回收 |
| 软引用 | SoftReference<Object> ref = new SoftReference<>(obj) |
内存不足时回收(OOM 前触发) |
| 弱引用 | WeakReference<Object> ref = new WeakReference<>(obj) |
下次 GC 必回收 |
| 虚引用 | PhantomReference<Object> ref = new PhantomReference<>(obj, queue) |
无法通过引用访问对象 |
五、实践验证(代码示例)
public class GCDemo {
public static void main(String[] args) {
// 强引用对象
Object obj = new Object();
// 虚引用队列
ReferenceQueue<Object> queue = new ReferenceQueue<>();
PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue);
obj = null; // 断开强引用
System.gc(); // 触发 GC
// 检查虚引用是否被回收
System.out.println("PhantomRef enqueued: " + (queue.poll() != null)); // 输出 true
}
}
六、关键注意事项
- 循环引用问题
JVM 的可达性分析能正确处理循环引用(如A→B→A),只要从 GC Roots 不可达即回收。 - 方法区回收
类的卸载需要更严格的条件(所有实例被回收 + 类加载器被回收)。 - Full GC 触发条件
老年代空间不足、元空间不足、主动调用System.gc()等场景会触发完整回收。
通过可达性分析,JVM 能精确判断对象是否可回收,这是现代垃圾回收器(如 G1、ZGC)高效运作的理论基础。开发者应避免通过 finalize() 干预回收逻辑(因其不可靠且性能差),而是通过合理管理对象引用来优化内存使用。
类的回收
在 JVM 中,判断类是否可以回收(类卸载) 的条件比普通对象更严格,其核心逻辑与类加载器和可达性相关。以下是类卸载的判定规则和流程:
一、类卸载的必要条件
一个类要被垃圾回收,需 同时满足 以下条件:
- 所有实例已回收
- 堆中不存在该类的任何实例对象(包括子类实例)。
- 类加载器已回收
- 加载该类的
ClassLoader实例本身不可达(无 GC Roots 引用)。
- 加载该类的
- Class 对象不可达
- 该类对应的
java.lang.Class对象未被任何地方引用(如反射、静态变量等)。
- 该类对应的
- 未注册本地方法或 JNI 引用
- 没有通过 JNI(Java Native Interface)引用该类。
二、类卸载的触发时机
类的卸载通常发生在以下两种场景:
- Full GC 期间
- 在 Full GC 过程中,JVM 会检查元空间(Metaspace)中的类元数据。
- 通过
UnloadingClassLoader标记不可达的类加载器。
- 元空间内存不足时
- 当 Metaspace 使用量达到
-XX:MaxMetaspaceSize阈值,触发 Full GC 尝试卸载类。
- 当 Metaspace 使用量达到
三、类卸载的典型场景
| 场景 | 示例 | 是否可卸载 |
|---|---|---|
| 自定义类加载器加载的类 | Tomcat 中 Web 应用的类(每个应用使用独立类加载器) | ✅ 应用卸载时可卸载 |
| Bootstrap 类加载器加载的类 | java.lang.String 等核心类 |
❌ 永不卸载 |
| 反射生成的临时类 | 动态代理类(如 JDK Proxy/CGLIB) | ✅ 无引用后可卸载 |
| 静态变量持有 Class 对象 | public static Class<?> clazz = MyClass.class; |
❌ 无法卸载 |
四、监控类卸载
1. JVM 参数
-XX:+TraceClassUnloading # 打印类卸载日志
-XX:+PrintClassHistogram # 查看类实例统计
2. 工具命令
jcmd <pid> GC.class_stats # 查看类元数据占用(需开启 -XX:+UnlockDiagnosticVMOptions)
jmap -clstats <pid> # 显示类加载器统计信息
五、类卸载的常见问题
1. 内存泄漏场景
-
静态集合持有 Class 对象
public class Leak { private static Set<Class<?>> classes = new HashSet<>(); public static void register(Class<?> clazz) { classes.add(clazz); // 阻止 Class 对象回收 } }
2. 框架陷阱
- Spring 代理类泄漏
若动态代理类被缓存且未及时清理,会导致类加载器无法回收。
六、强制类卸载(高风险操作)
通过反射调用 sun.misc.Unsafe 可强制卸载类(仅用于测试):
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
unsafe.defineAnonymousClass(...); // 强制释放类元数据(谨慎使用!)
总结
- 类卸载是 JVM 自动行为,开发者通常无需干预。
- 关键点:控制类加载器生命周期,避免静态引用和 JNI 泄漏。
- 优化方向:对需要动态加载/卸载类的场景(如插件化系统),使用独立类加载器并确保及时销毁。
Minor GC、Full GC 及其他 GC
以下是关于 Minor GC、Full GC 及其他 GC 类型 的详细解析,包含区别、作用及实际场景对比:
一、GC 分类与核心概念
1. Minor GC (Young GC)
- 作用区域:新生代(Young Generation,包括 Eden + Survivor 区)
- 触发条件:
- Eden 区空间不足时触发
- 新对象无法分配时自动启动
- 执行过程:
- 标记 Eden 和 Survivor 区的存活对象
- 存活对象复制到另一个 Survivor 区(复制算法)
- 年龄计数器增加,达到阈值(默认15)则晋升老年代
- 特点:
- 频率高(短周期小对象频繁创建时)
- STW 时间短(通常毫秒级)
- 使用 复制算法(高效无碎片)
2. Major GC (Old GC)
- 作用区域:老年代(Old Generation)
- 触发条件:
- 老年代空间不足(如对象晋升失败)
- 显式调用
System.gc()(不推荐)
- 执行过程:
- 标记老年代存活对象(标记-清除或标记-整理算法)
- 清理不可达对象,整理内存空间
- 特点:
- 频率低(长生命周期对象较少时)
- STW 时间较长(秒级,取决于堆大小)
- 常伴随 Full GC(部分资料将 Major GC 等同于 Full GC)
3. Full GC (全局GC)
- 作用区域:整个堆 + 方法区(Metaspace)
- 触发条件:
- 老年代空间不足(Major GC 后仍不足)
- Metaspace 空间不足(类元数据过多)
- 代码调用
System.gc() - 堆内存担保失败(Young GC 前预测老年代空间不足)
- 执行过程:
- 全堆可达性分析(标记-清除-整理)
- 清理所有代的内存空间
- 卸载不再使用的类(类回收)
- 特点:
- STW 时间长(秒到分钟级,影响严重)
- 应尽量避免频繁 Full GC
二、其他 GC 类型
1. Mixed GC (混合GC,G1 特有)
- 作用区域:新生代 + 部分老年代分区
- 触发条件:
- G1 的 Heap 占用率达到阈值(
-XX:InitiatingHeapOccupancyPercent,默认45%)
- G1 的 Heap 占用率达到阈值(
- 特点:
- 增量回收老年代(避免一次性全堆回收)
- 可控的停顿时间(通过
-XX:MaxGCPauseMillis设定)
2. System GC
- 手动触发:通过
System.gc()或Runtime.getRuntime().gc()调用 - 问题:
- 触发 Full GC(可能影响性能)
- 可通过
-XX:+DisableExplicitGC禁用
3. Meta GC (元空间GC)
- 作用区域:Metaspace
- 触发条件:
- Metaspace 使用量超过
-XX:MetaspaceSize - 类卸载时释放元数据空间
- Metaspace 使用量超过
三、GC 类型对比表
| GC 类型 | 作用区域 | 触发条件 | 执行速度 | STW 时间 | 对应用影响 |
|---|---|---|---|---|---|
| Minor GC | 新生代 | Eden 区满 | 快 | 毫秒级 | 低 |
| Major GC | 老年代 | 老年代空间不足 | 慢 | 秒级 | 高 |
| Full GC | 全堆 + Metaspace | 老年代/Metaspace 不足 | 最慢 | 秒~分钟级 | 严重 |
| Mixed GC | 新生代+部分老年代 | G1 堆占用阈值 | 中等 | 可控停顿 | 中 |
四、GC 触发逻辑示例
graph TD
A[新对象分配] --> B{Eden 区是否足够?}
B -->|是| C[分配成功]
B -->|否| D[触发 Minor GC]
D --> E{Minor GC 后空间是否足够?}
E -->|是| C
E -->|否| F{是否允许担保失败?}
F -->|是| G[尝试将对象直接存入老年代]
G --> H{老年代空间是否足够?}
H -->|是| I[分配成功]
H -->|否| J[触发 Full GC]
F -->|否| J
五、调优建议与监控
1. 减少 Full GC 的策略
- 增大新生代比例:
-XX:NewRatio=2(老年代:新生代=2:1) - 避免大对象直接进入老年代:调整
-XX:PretenureSizeThreshold - Metaspace 监控:设置
-XX:MaxMetaspaceSize防止元数据膨胀
2. 关键监控命令
# 查看 GC 统计
jstat -gcutil <pid> 1000 # 每秒输出一次 GC 统计
# 分析 GC 日志(需开启参数)
-XX:+PrintGCDetails -Xloggc:/path/to/gc.log
# 堆内存直方图
jmap -histo:live <pid>
六、常见误区澄清
- Major GC ≠ Full GC
Major GC 仅针对老年代,Full GC 包含全堆和方法区。 - 频繁 Minor GC 不一定有问题
高频短时 Minor GC 可能优于偶发的长时 Full GC。 - System.gc() 不保证立即执行
JVM 可能忽略此请求或延迟处理。
通过合理配置堆大小、选择垃圾回收器(如 G1/ZGC)及监控 GC 行为,可显著优化 Java 应用的停顿时间和吞吐量。
JVM问题分析
以下是 JVM 问题分析的常用工具和方法指南,包含 Thread Dump、Heap Dump 的获取与分析全流程:
一、核心诊断工具清单
| 工具类型 | 工具名称 | 适用场景 |
|---|---|---|
| 线程分析 | jstack、Arthas、JMC | 死锁/CPU 高/线程阻塞 |
| 内存分析 | jmap、MAT、JProfiler | 内存泄漏/OOM |
| 监控统计 | jstat、VisualVM | GC 频率/内存分布实时监控 |
| 在线诊断 | Arthas、BTrace | 生产环境无侵入式分析 |
| 日志分析 | GC 日志分析工具 | GC 停顿优化 |
二、Thread Dump 获取与分析
1. 获取 Thread Dump 的方法
(1) 命令行工具 jstack
# 获取当前线程快照
jstack -l <PID> > thread_dump.txt
# 连续抓取(间隔2秒,抓3次)
for i in {1..3}; do jstack -l <PID> > thread_$i.txt; sleep 2; done
(2) Arthas 在线诊断
# 启动 Arthas
java -jar arthas-boot.jar
# 生成线程快照
thread --all > thread_dump.txt
# 统计最忙线程(CPU 占用)
thread -n 3
(3) kill 信号触发(Linux)
kill -3 <PID> # 输出到标准错误(需应用有控制台输出重定向)
2. Thread Dump 分析要点
- 死锁检测:搜索
deadlock或BLOCKED状态线程 - CPU 高负载:查找
RUNNABLE状态且长时间运行的线程 - 线程阻塞:关注
WAITING/TIMED_WAITING状态的堆栈 - 线程池问题:检查线程池工作队列堆积情况
示例:定位 CPU 100% 问题
"http-nio-8080-exec-1" #32 daemon prio=5 os_prio=0 cpu=152341ms elapsed=212.34s
java.lang.Thread.State: RUNNABLE
at com.example.LoopService.infiniteLoop(LoopService.java:17) # 定位到死循环代码行
三、Heap Dump 获取与分析
1. 获取 Heap Dump 的方法
(1) 命令行工具 jmap
# 生成堆转储文件
jmap -dump:live,format=b,file=heap.hprof <PID>
# 仅获取堆直方图(快速分析)
jmap -histo:live <PID> > heap_histo.txt
(2) JVM 参数触发 OOM 时自动生成
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/path/to/dumps
(3) VisualVM/JProfiler 图形化操作
- 连接进程 → 点击 “Heap Dump” 按钮
2. Heap Dump 分析工具
(1) Eclipse MAT (Memory Analyzer Tool)
- Dominator Tree:查找占用内存最大的对象
- Leak Suspects:自动分析内存泄漏可疑点
- Path to GC Roots:查看对象引用链
(2) JProfiler
- All Objects:按类/包统计内存占用
- Biggest Objects:可视化大对象分布
示例:内存泄漏分析
// MAT 分析结果示例
Problem Suspect 1: 50.3MB (72.5%) by java.util.HashMap$Node[]
-> com.example.Cache.staticMap // 静态 Map 未清理导致泄漏
四、其他关键工具使用
1. 实时监控工具 jstat
# 监控 GC 行为(间隔1秒持续输出)
jstat -gcutil <PID> 1000
# 输出列说明:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.0 0.0 75 41.3 95.12 90.23 15 0.250 3 1.500 1.750
2. 图形化工具 VisualVM
- 功能:实时监控堆/线程/CPU,抽样分析热点方法
- 插件扩展:安装 MBeans 插件监控 JVM 内部指标
3. 线上诊断神器 Arthas
# 监控方法执行耗时
watch com.example.Service * '{params, returnObj}' -x 3 -n 5
# 追踪类加载来源
sc -d com.example.MyClass
# 热更新代码(紧急修复)
redefine /path/to/new.class
五、实战分析流程示例
案例 1:CPU 飙升问题
- 获取线程快照:
top -Hp <PID>找高 CPU 线程 →jstack转十六进制线程 ID - 分析堆栈:定位处于
RUNNABLE状态的业务代码 - 复现验证:用 Arthas 的
monitor命令统计方法调用频率
案例 2:内存泄漏排查
- 观察内存趋势:
jstat -gcutil查看老年代占用是否持续增长 - 生成 Heap Dump:在 OOM 前或手动触发
jmap - MAT 分析:查找 Dominator Tree 中的异常大对象
六、注意事项
- 生产环境慎用:
jmap和 Full GC 可能导致应用停顿 - 文件管理:Heap Dump 文件可能极大(与堆大小相当)
- 权限控制:线上诊断工具需要权限隔离(如 Arthas 安全沙箱)
- 时间戳对齐:同时记录问题发生时间与日志/Dump 生成时间
掌握这些工具的组合使用,可以快速定位以下典型问题:
- 🕹 线程问题:死锁、线程池耗尽、异步任务堆积
- 💾 内存问题:内存泄漏、不合理缓存、大对象分配
- ⏱ GC 问题:频繁 Full GC、长停顿、晋升失败
- 🔥 性能问题:锁竞争、慢 SQL、算法低效
建议在测试环境预先演练工具使用,确保生产环境出现问题时能快速响应。
类加载
以下是关于 Java 类加载机制、步骤及自定义类加载器的详细讲解:
一、类加载机制核心原理
1. 类加载的生命周期
graph LR
A[加载 Loading] --> B[验证 Verification]
B --> C[准备 Preparation]
C --> D[解析 Resolution]
D --> E[初始化 Initialization]
E --> F[使用 Using]
F --> G[卸载 Unloading]
- 加载 → 验证 → 准备 → 解析 → 初始化 是严格顺序(解析可能在初始化后)
- 卸载由 JVM 自动管理(需满足类卸载条件)
二、类加载的详细步骤
1. 加载(Loading)
- 任务:查找并加载类的二进制字节流
- 数据来源:
- 本地文件系统(
.class文件) - 网络下载(Applet)
- 动态生成(动态代理)
- 其他(ZIP/JAR 包)
- 本地文件系统(
- 结果:在堆中生成
java.lang.Class对象
2. 验证(Verification)
- 目的:确保字节码符合 JVM 规范
- 验证项:
- 文件格式验证(魔数
0xCAFEBABE) - 元数据验证(继承/实现是否合法)
- 字节码验证(方法体逻辑)
- 符号引用验证(能否找到引用的类/方法)
- 文件格式验证(魔数
3. 准备(Preparation)
-
任务:为 类变量(static) 分配内存并设置初始值
-
示例:
public static int value = 123; // 准备阶段 value = 0(零值) // 初始化阶段 value = 123
4. 解析(Resolution)
- 任务:将常量池中的符号引用替换为直接引用
- 符号引用:以文本形式描述引用的目标(如
java/lang/Object) - 直接引用:指向目标内存地址的指针或偏移量
5. 初始化(Initialization)
- 任务:执行类构造器
<clinit>()方法(编译器自动生成) - 触发条件:
- 首次创建类实例
- 访问类的静态变量/方法(非 final)
- 反射调用(
Class.forName()) - 子类初始化触发父类初始化
三、双亲委派模型(Parents Delegation Model)
1. 类加载器层级
graph BT
A[应用程序类加载器 AppClassLoader] --> B[扩展类加载器 ExtClassLoader]
B --> C[启动类加载器 BootstrapClassLoader]
D[自定义类加载器] --> A
2. 工作流程
graph TD
A[子类加载器收到加载请求] --> B{是否已加载?}
B -->|否| C[委派父类加载器]
C --> D{父类能否加载?}
D -->|是| E[使用父类结果]
D -->|否| F[自行加载]
B -->|是| G[返回已加载类]
- 优势:
- 避免重复加载(如
java.lang.Object) - 防止核心类被篡改(安全沙箱)
- 避免重复加载(如
3. 破坏双亲委派的场景
- SPI 机制:JDBC 驱动加载(线程上下文类加载器)
- 热部署:OSGi、Tomcat Webapp 隔离
四、自定义类加载器实战
1. 实现步骤
- 继承
ClassLoader类 - 重写
findClass()方法 - 读取字节码 → 调用
defineClass()
2. 代码示例
public class MyClassLoader extends ClassLoader {
private String classPath;
public MyClassLoader(String classPath) {
this.classPath = classPath;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try {
byte[] data = loadClassData(name);
return defineClass(name, data, 0, data.length);
} catch (IOException e) {
throw new ClassNotFoundException(name, e);
}
}
private byte[] loadClassData(String className) throws IOException {
String path = classPath + File.separatorChar +
className.replace('.', File.separatorChar) + ".class";
try (InputStream is = new FileInputStream(path);
ByteArrayOutputStream bos = new ByteArrayOutputStream()) {
int len;
byte[] buffer = new byte[1024];
while ((len = is.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
return bos.toByteArray();
}
}
// 测试代码
public static void main(String[] args) throws Exception {
MyClassLoader loader = new MyClassLoader("/tmp/classes");
Class<?> clazz = loader.loadClass("com.example.MyClass");
Object obj = clazz.newInstance();
System.out.println(obj.getClass().getClassLoader()); // 输出 MyClassLoader
}
}
3. 关键注意事项
-
命名空间隔离:不同类加载器加载的类互不可见
-
打破双亲委派:重写
loadClass()而非findClass()@Override public Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { Class<?> c = findLoadedClass(name); if (c == null) { // 自定义逻辑:特定包不走双亲委派 if (name.startsWith("com.example.myapp")) { c = findClass(name); } else { c = super.loadClass(name, resolve); } } if (resolve) { resolveClass(c); } return c; } }
五、类加载器应用场景
| 场景 | 实现方式 | 典型案例 |
|---|---|---|
| 热部署 | 自定义类加载器重新加载类 | Tomcat 的 WebappClassLoader |
| 模块化 | 每个模块使用独立类加载器 | OSGi 框架 |
| 加密保护 | 自定义类加载器解密字节码 | 商业软件代码保护 |
| 版本隔离 | 不同类加载器加载不同版本库 | Spring Boot 嵌套 JAR |
六、常见问题排查
1. ClassNotFoundException vs NoClassDefFoundError
- ClassNotFoundException:类加载器在加载阶段找不到类
- NoClassDefFoundError:类已加载过,但初始化失败或后续被删除
2. 类加载器内存泄漏
- 症状:Metaspace 持续增长
- 原因:静态集合持有 ClassLoader 引用
- 定位:使用
jmap -clstats <pid>查看类加载器统计
通过理解类加载机制和自定义类加载器实现,可以应对模块化部署、热更新等高级需求,同时为 JVM 调优和故障排查提供理论基础。
SPI机制
以下是关于 SPI(Service Provider Interface)机制 的详细解析,包含核心原理、实现流程及典型应用场景:
一、SPI 机制核心原理
1. 基本概念
- SPI(服务提供者接口):一种 接口与实现解耦 的动态扩展机制,允许第三方为接口提供具体实现,并由框架在运行时自动发现和加载。
- 核心思想:面向接口编程 + 服务发现机制,实现 开闭原则(对扩展开放,对修改关闭)。
2. 与 API 的区别
| 特性 | API(Application Programming Interface) | SPI(Service Provider Interface) |
|---|---|---|
| 定义方 | 由服务提供方定义接口,调用方直接使用 | 由框架定义接口,第三方提供实现 |
| 调用方向 | 调用方 → 实现方(由应用开发者调用) | 实现方 → 框架(由框架反向调用实现类) |
| 典型场景 | Java 标准库方法(如 List.add()) |
JDBC 驱动、日志门面(如 SLF4J) |
二、Java SPI 实现机制
1. 核心组件
- 接口定义:由框架或标准库提供(如
java.sql.Driver)。 - 服务提供者:实现接口的具体类(如
com.mysql.cj.jdbc.Driver)。 - 配置文件:
META-INF/services/<接口全限定名>,内容为实现类的全限定名。 - 服务加载器:
java.util.ServiceLoader,负责加载和实例化服务提供者。
2. 工作流程
graph TD
A[定义SPI接口] --> B[服务提供者实现接口]
B --> C[在META-INF/services下注册实现]
C --> D[ServiceLoader加载服务]
D --> E[框架使用服务实例]
详细步骤:
-
接口定义
public interface DataStorage { void save(String data); } -
服务提供者实现
public class FileStorage implements DataStorage { @Override public void save(String data) { // 保存到文件系统 } } -
注册实现类
创建文件:META-INF/services/com.example.DataStorage
内容:com.example.FileStorage -
服务加载与使用
ServiceLoader<DataStorage> loader = ServiceLoader.load(DataStorage.class); for (DataStorage storage : loader) { storage.save("data"); // 调用所有实现类 }
三、SPI 的典型应用场景
1. JDBC 驱动加载
- 接口:
java.sql.Driver - 实现:MySQL Driver(
com.mysql.cj.jdbc.Driver)、PostgreSQL Driver 等 - 配置文件:
META-INF/services/java.sql.Driver - 加载过程:
DriverManager初始化时通过 SPI 加载所有注册的驱动。
2. 日志门面(SLF4J)
- 接口:
org.slf4j.LoggerFactory - 实现:Logback(
ch.qos.logback.classic.LoggerContext)、Log4j2 等 - 桥接原理:通过 SPI 动态绑定具体日志实现。
3. Spring Boot 自动配置
- 扩展点:
spring.factories文件(SPI 增强版) - 注册方式:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.example.MyAutoConfiguration
4. Dubbo 扩展机制
- 特点:改进的 SPI(支持按需加载、自适应扩展)
- 配置文件:
META-INF/dubbo/com.alibaba.dubbo.rpc.Protocol - 扩展点:协议(Protocol)、负载均衡(LoadBalance)等。
四、SPI 机制优缺点
优点
- 解耦性强:接口与实现分离,便于模块化扩展。
- 动态发现:新增服务提供者无需修改框架代码。
- 标准化扩展:统一的服务注册方式,降低接入成本。
缺点
- 全量加载:
ServiceLoader会实例化所有实现类(即使未使用)。 - 配置敏感:配置文件路径和格式错误会导致加载失败。
- 无优先级:无法指定实现类的加载顺序。
五、高级应用:自定义 SPI 增强
1. 按需加载优化
public class SelectiveServiceLoader {
public static <S> S loadFirst(Class<S> service) {
return ServiceLoader.load(service).findFirst().orElseThrow();
}
}
// 使用示例
DataStorage storage = SelectiveServiceLoader.loadFirst(DataStorage.class);
2. 结合注解过滤
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface Priority {
int value() default 0;
}
// 加载时按优先级排序
List<DataStorage> storages = ServiceLoader.load(DataStorage.class).stream()
.map(Provider::get)
.sorted((a, b) -> b.getClass().getAnnotation(Priority.class).value()
- a.getClass().getAnnotation(Priority.class).value())
.collect(Collectors.toList());
六、SPI 实现原理源码解析
关键源码片段(ServiceLoader)
public final class ServiceLoader<S> implements Iterable<S> {
// 加载实现类的核心方法
private boolean hasNextService() {
if (configs == null) {
// 读取 META-INF/services/ 下的配置文件
String fullName = PREFIX + service.getName();
configs = loader.getResources(fullName);
}
while ((pending == null) || !pending.hasNext()) {
// 解析配置文件中的类名
String cn = nextName();
Class<?> c = Class.forName(cn, false, loader);
providers.put(cn, c.newInstance());
}
return true;
}
}
七、最佳实践与注意事项
-
配置文件管理
- 确保文件编码为 UTF-8。
- 避免重复注册同一接口的实现。
-
类加载器选择
-
使用线程上下文类加载器以兼容容器环境:
ServiceLoader.load(service, Thread.currentThread().getContextClassLoader());
-
-
性能优化
- 缓存服务实例避免重复加载。
- 使用
@PostConstruct延迟初始化。
通过 SPI 机制,Java 生态实现了高度可扩展的架构设计。掌握其原理与扩展技巧,可大幅提升框架的灵活性和开发者体验。